
In-Order Instruction Pipelining in Processors

Disclaimer: Opinions shared in this, and all my posts are mine, and mine alone. They do not reflect the views of my employer(s), and are not investment advice.
Before going into this topic, I want to define the way I am using some terms here:
What is a CPU pipeline?
It is the set of hardware components needed to “execute” instructions. To execute means:
Be able to read an instruction by specifying its location, and decode what the bits mean
Perform some arithmetic, logic and data movement operations
Be able to read and write data to memory - for writes, send data and address, and for reads, send address, receive data
Some interrupt mechanism to stop current instruction execution
Some common terms used interchangeably:
A core: Usually, a core is a pipeline + some data and instruction caches
A processor: Usually has multiple cores, a centralized memory system, and connections to route data between all these.
Significance of “in-order”
Instructions can only be fetched in the order they are written (by the compiler, in some memory location)
If branch instructions are encountered, the order may change, but that is how the program is meant to be executed - the hardware has no role in changing the order
How do we define performance?
There are two common performance metrics for cores:
Throughput: The number of instructions that complete execution per unit of time
Latency: The time it takes for one instruction to go from the start to the end of the pipeline
With that out of the way, let us understand in-order pipelining in more detail.
Some History about Pipelining
Ideas of pipelining long predate modern computers. The earliest at-scale implementation of something that resembles CPU pipelines was seen in 1913 - when Henry Ford introduced the moving assembly line, which reduced the time to build a car by more than 10 times.
While it is debatable what could be considered “pipelining” by today’s definition, one of the earliest implementation of this idea in computers belong to someone I only heard of while researching for this piece - the German Civil Engineer Konrad Zuse. Between 1936 and 1941, the midst of the holocaust, Zuse came up with the Z1 and Z3 computers. Remember that the transistor was invented only in 1947, so these were mechanical computers (the Z3 was based on electromechanical relays). A structure resembling modern CPU pipelines can be seen in Z3 architecture described by R. Rojas in the paper "Konrad Zuse's legacy: the architecture of the Z1 and Z3,”. Unfortunately, the Z3 was destroyed in 1943 during a bombing raid on Berlin.

Z3 execution pipeline as depicted in https://ieeexplore.ieee.org/document/586067
After the advent of transistor based computers, IBM was the first to introduce pipelining in the IBM 7030 (Known internally as IBM Stretch). Pipelining (referred to as “simultaneous operation” at that time), was so effective, that this supercomputer remained the fastest in the world at that time for about 3 years.
In early 1960s, pipelining was restricted to supercomputers and university research projects (like the ILLIAC II project at University of Illinois, Urbana). In 1967, IBM was the first to use the idea of pipelining for commercial processors by releasing the IBM System/360 Model 91 in 1967. This was still a mainframe - microprocessors were only released in 1970s.
The Motorola 68020, released in 1984, is often cited as one of the first microprocessors with a pipeline. Intel followed this trend, with a partially pipelined design in the 80386 in 1985, and the now common, 5-stage full pipeline in the 80486 in 1989. After this, pipelining became a standard feature in all processors. (In fact I tried, but couldn’t find a well-known modern processor that does not have a pipeline, even among low-performance ones)
Why pipelining?
All digital systems change “states” in intervals decided by clock signals - so if the frequency of the clock is higher, the pipeline can complete more state changes in fewer seconds, which will eventually result in higher throughput.
However, there is a minimum time period that the clock needs to have to support a given digital logic between the start and end of the pipeline. To reduce this time period (i.e. increase frequency), we need to break up the task into multiple stages, and each stage is completed in one “smaller” clock cycle.
Let me try to explain the concept of pipelining with an analogy based on laundry. Let’s say you have a fully automatic washing machine - once you load the dirty clothes, it runs the washer, then the dryer, and in the end you get clean clothes. Let’s say the washer takes 10 minutes and dryer takes 20 minutes - the total time spent for one load is 30 minutes. For 2 loads, it is going to be 60 minutes, and increases by 30 minutes for each new load.
Now imagine you decided to get separate machines - one for washing, and one for drying. Lets assume each of them still takes the same time - i.e. 10 minutes for the washer, 20 minutes for the dryer. The time taken for the first load is still 30 minutes. However, when the first load is in the dryer, the second load can be put in the washer. This way, you are able to complete 2 loads in 50 minutes, and a every subsequent load only takes 20 minutes. That’s the advantage of pipelining - throughput is decided only by the time takes for the slowest stage - not the total time.
Even with a very efficient system to move clothes between your washer and dryer, you will need to spend some time that would not be needed by the automatic machine. Lets say it takes you 2 minutes of overhead. So the second load actually finishes at 52 minutes, not 50. Remember, we started the washer for second load after 10 minutes. Latency is defined as the time from start to finish, so the latency for each load is 42 minutes. This is higher than the automatic case, which has a latency of 30 minutes. (The throughput time also increases slightly to 22 minutes, but it is still better than 30 minutes for the automatic case)
Now imagine a system, where the washer also has a 5 minute spin dry at the end, and as a result we only need 15 minutes in the dryer. This makes both stages an even 15 minutes. Now, the second load completes at 45 minutes (47 with the overhead), and every subsequent load only takes 15 minutes (17 with overhead) to complete. Interestingly, the latency also reduces to 32 minutes - which is just 2 minutes more than the single stage case.
This is the summary of completion time in minutes for the example above:

This analogy highlights why pipelining is useful. In a pipelined processor the instruction execution is divided into multiple stages to increase the throughput. For most applications that require the execution of multiple instructions, the throughput gain is much more important than the small latency penalty , which makes pipelining a standard feature in all modern processors.
A Traditional CPU Pipeline
In a typical processor, there is a 5 stage pipeline:
Instruction Fetch (IF)
Operand Fetch and Decode (OF)
Execute (EX)
Memory Access (MA)
Register Write Back (RW)
To understand each stage better, let us consider the following instructions executing on a 5 stage CPU pipeline (with a lot of simplifying assumptions)
LOAD R1, R0, 5
MOV R5, 5
ADD R3, R2, 4
MOV R2, 3
SUB R4, R3, R1
STORE R0, R4
In the first cycle, the LOAD instruction is placed in the Instruction Fetch stage - which indicates that the pipeline has read the bits for the instruction from a memory.
In the next cycle, this LOAD instruction moves to the Operand Fetch and Decode stage - which is where the pipeline understands what the bits of the instruction means. For this made-up instruction, we can assume that the bits indicate this instruction should get data from register R0, add 5 to that value, and use that as the memory address. Then, it needs to fetch the data from this memory location and place it in register R1. Once the decoding is done in this stage, the data from register R0 is fetched in the same stage. (Registers are a type of storage local to the pipeline - we are assuming that we can read the data in registers at the end of this cycle). Also, now that LOAD is in the OF stage, the IF stage is empty - so the next instruction - MOV is fetched.
Cycle 3 sees LOAD in the execute stage, where all the arithmetic operations are done - add 5 to the value in register R0 to get the memory address. In the same cycle, the MOV instruction gets decoded in the OF stage, and the ADD instruction moves to the IF stage.
In cycle 4, the LOAD instruction can access memory to read the data from the memory address that was calculated in the EX stage in the previous cycle. We assume that the data at this memory address can be read at the end of this cycle (Usually memory access takes multiple cycles, so this is a major simplification). In the same cycle, MOV is in the EX stage (although no arithmetic operation is needed), ADD moves to OF stage (register R2 is read), and the second MOV is in the IF stage.
Cycle 5 is the last cycle for LOAD. As the name indicates, the register write-back stage is where data is written into registers - in this case, data that was requested in MA stage is written to register R1. At the end of this cycle, all the work that needs to be done for the LOAD instruction is completed, and the instruction leaves the pipeline. Other instructions continue to move through the pipeline - MOV to MA (no memory access needed), ADD to EX (compute: data from register R2 + 4), MOV to OF (decode instruction, no register fetch), and SUB to IF. An interesting point to note here is that the value of R2 that ADD uses was fetched in cycle 4 - this is not overwritten by the MOV R2, 3 instruction that was fetched in that cycle. Register and Memory writes should always be done in program order.
Cycle 6 is the last cycle for instruction 2 - MOV R5, 5. In this cycle, the value 5 is written to register R5. (Notice how this is the only cycle were MOV actually does work - not all instructions use all the pipeline stages, but they still need to go through the pipeline in the program order). We also see ADD instruction in MA (no memory access needed), MOV in EX (no arithmetic operation), SUB in OF, and the new STORE instruction in IF.
The SUB instruction is interesting - it needs to fetch data for 2 registers in this cycle - R1 and R3. The register value to R1 was just written in the previous cycle by LOAD instruction, so the correct value is available. But if SUB was sent into the pipeline one cycle earlier (Let’s say in place of MOV R2, 3), it would not have the updated value - this is called a Data Hazard, and pipelines need a way to handle such cases. (A future topic not covered here)
This table shows the different instructions at different stages in each cycle:
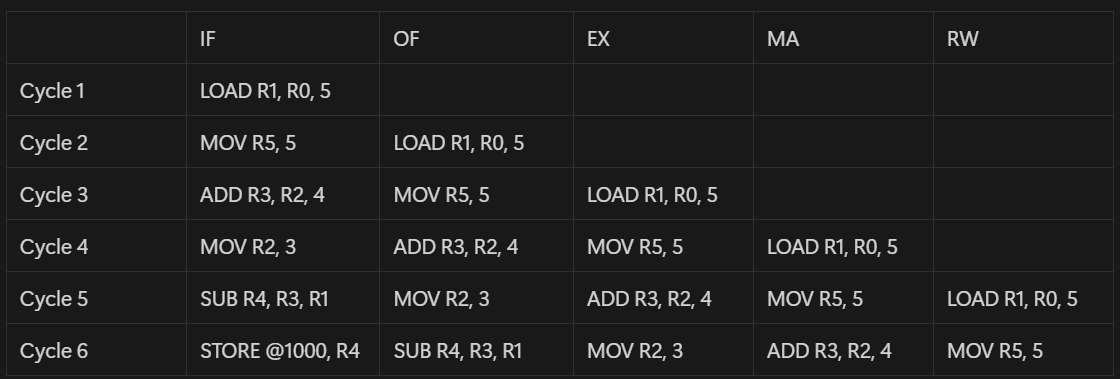
This example demonstrates the basic principle of instruction pipelining in a 5-stage CPU pipeline. Note here that after cycle 5, we expect 1 instruction to be completed at the end of each cycle (assuming no dependencies between instructions). If we assume each cycle take 1 second, the throughput is 1 instruction per second. If we assume that it takes 0.1s for the instruction to move from one stage to another, and each stage completes in one cycle (1 second), the latency would be 1 (IF) + 0.1 (IF to OF) + 1 (OF) + 0.1 (OF to EX) + 1 (EX) + 0.1 (EX to MA) + 1 (MA) + 0.1 (MA to RW) + 1 (RW) = 5.4 seconds. The same concept can be extended to more complex pipelines with different number and size of stages.
How to decide the right number of stages?
While the ideal number of stages is not set in stone, there are two ideal characteristics that your pipeline stages should have:
Each stage typically has similar amount of logic (The most efficient pipeline has all stages with equal delays - remember the washer with spin dryer in the earlier analogy)
There should be less overlap in functionality between the stages - this is important, because moving data between stages has a power, performance, and area cost.
Is more stages always better?
It is possible to break each of these stages into equally divided substages, and keep increasing the number of stages in the pipeline (Intel/AMD have ambitiously attempted processors codenamed NetBurst and Bulldozer - they have around 20 stages in their instruction pipeline).
Although pipelining has advantages, too many stages are not good for performance, because:
Ultimately, the clock period cannot be increased due to other physical limitations (Like register latch delays)
The cost of stopping the pipeline (a.k.a hazards) is significantly higher with more stages. We have not talked about hazards yet, but for now, imagine our analogy with a 10 stage laundry system, but you realize that you left an important document in the pocket of a shirt that is currently in stage 8. Think about how much time and effort it would take to recover that shirt. Unfortunately, such scenarios happen very often in processors.
Although not a performance reason, but higher frequency results in higher power consumption, which is why modern desktop processor frequencies have stalled in the 3-4 GHz range
Is pipelining enough?
Although pipelining provides significant benefits, it also adds new problems that a non-pipelined processor would not have - what happens to the instructions loaded to the pipeline if we need to stop - due to data dependencies, a branch instruction, or an interrupt (like divide by 0). Each one deserves separate treatment in future posts.
References:
Good History of CPUs - https://www.gamedev.net/tutorials/programming/general-and-gameplay-programming/a-journey-through-the-cpu-pipeline-r3115/
Z1 and Z3 architecture - https://ieeexplore.ieee.org/document/586067
IBM 730 (Stretch) - https://www.ibm.com/history/stretch
The Birth, Evolution and Future of Microprocessor - https://www.sjsu.edu/people/robert.chun/courses/CS247/s4/M.pdf
Intel Netburst - https://chipsandcheese.com/2022/06/17/intels-netburst-failure-is-a-foundation-for-success/
AMD Bulldozer - https://chipsandcheese.com/2023/01/22/bulldozer-amds-crash-modernization-frontend-and-execution-engine/