
Caches Deep Dive - Part 2: Optimization Techniques
How to build a faster memory architecture

Disclaimer: Opinions shared in this, and all my posts are mine, and mine alone. They do not reflect the views of my employer(s), and are not investment advice.
In part 1 of the Caches Deep Dive series, I covered some basic concepts in designing a cache. I recommend checking that out first for ideas here to make more sense. In this part, I will talk about how caches are used in real systems to improve performance.
Mathematical Analysis:
As I briefly mentioned in my previous post, every type of memory - cache, or main memory, takes some time to complete its task (either read or write) after receiving a memory request. This delay is called latency (I talked more about latency in one of my earlier post on pipelining). Let me define a few terms:
Hit Latency (T_hit): This is the latency (number of clock cycles) when the requested address results in a cache hit
Miss Penalty (T_miss): This is the additional time (number of clock cycles) it takes for cache to handle a miss request (cache needs to fetch/send data to next memory stage). During a miss, the cache also needs to spend T_hit to check for a hit/miss. So total time would be T_hit + T_miss.
Miss Probability (P_miss): This is the ratio of average number of cache misses to the total number of cache requests.
Our goal is to calculate the average latency of the memory (cache), which is called the Average Memory Access Time (AMAT). If all the memory requests to a cache are a hit, then the AMAT would be same as the Hit Latency. If all the memory requests are a miss, then AMAT includes both hit latency and miss penalty. In general, we can compute the AMAT of a cache as:
AMAT = T_hit + (P_miss * T_miss)
In my post on pipelining, I introduced another term - throughput - which is the number of instructions that complete execution per unit of time. A metric that is directly correlated with throughput is Cycles Per Instruction, or CPI. This is the average number of cycles each instruction takes (Total cycles / Total instructions). A lower CPI corresponds to higher throughout (and since most systems today are throughput bound - this results in a faster system)
To understand the impact of memory latency, let us define few terms:
Optimal CPI (CPI_opt): This is the value of CPI if all the memory requests result in a cache hit (Best case scenario)
Memory Instruction Rate (P_mem): The ratio of number of memory instructions to the total number of instructions in a workload.
If our system is designed in a way that all memory accesses are cache hits, then the CPI would be same as CPI_opt. However, if there are misses, additional cycles need to be added. This gives us the following equation for CPI:
CPI = CPI_opt + (P_mem * (AMAT - T_hit))
-> CPI = CPI_opt + (P_mem * (P_miss * T_miss))
(Above equation may not be very accurate for out-of-order processors, but that’s a topic for another day)
From this equation, it is clear that there are different ways to reduce CPI (and increase throughput). The two options beyond the scope of this post are:
Reduce CPI_opt
This mostly includes non-memory aspects of the processor, which I’m not covering here. However, CPI_opt also depends on the Hit Latency (T_hit) of the cache directly interacting with the processor. This is done by designing a faster cache (which often means a smaller cache). Some of the ideas discussed in the caches deep dive - part 1 will help achieve this goal.
Reduce P_mem
Usually, this is achieved using a smarter compiler and better ISA - If the compiler can reduce the number of memory accesses needed for a workload, P_mem is lower. To know more about ISAs, check out my earlier post on the topic.
The above methods are also very important aspects of computer architecture. However, in this post, we will focus on Miss Probability (P_miss) and Miss Penalty (T_miss). The goal of a good memory architect is to reduce these numbers. Rest of this post is dedicated to methods that help achieve this.
Approach 1: Reducing the Miss Probability
To understand how to reduce the rate of cache misses, let me first talk about the different types of cache misses, popularly known as the 3 C’s:
Compulsory/Cold Misses
In general, a cache starts empty before a workload is executed by a processor. In this case, even if the workload only accesses one memory address, the first request will be a cache miss - the cache needs to fetch the first cache block from memory. Also, the first access to each cache block also results in a miss - for example, if you want to access addresses 100, 101, 102, 103 repeatedly, and the cache block can hold 4 addresses, the first access would be a miss (every subsequent access is a hit). Such a miss is called compulsory miss.
Capacity Misses
Let’s say you have a cache that can hold 4 memory locations. If your workload has a loop which needs to access 8 memory location for each iteration of the loop - you are inevitably going to have misses, irrespective of the policy you use to add/remove cache blocks. Such a miss, caused by limited cache capacity, is called a capacity miss.
Conflict Misses
A conflict miss is one, that is caused by inefficient mapping of addresses from main memory to the cache. I have covered mapping in more detail in my previous post. For example, if we have a workload with a loop that accesses address = 100, followed by address = 200 repeatedly, but our cache mapping places both addresses in the same cache index - then every memory request would result in a cache miss. There is important distinction between Conflict and Capacity miss - if in the example described, the cache only has a capacity to store 1 memory address - it would be a capacity miss, not a conflict miss. However, if we have a capacity of more than 1 address, then a different cache mapping can avoid conflicts and result in cache hit - hence it would be a conflict miss.
** In reality, there are 4 C’s - the fourth being “Coherence Misses”. These only occur in multi-core systems, so I am not talking about them.
How to reduce compulsory misses:
Bigger cache blocks
If the goal is to just reduce compulsory misses, then having bigger cache blocks helps - this is why a cache block usually has more than one address (or word). However, there are diminishing returns to increasing the cache size after a point. If taken to an extreme, if a cache just has one block with all addresses, you will only have a compulsory miss for the first access for the workload. But if you think this through, all its really doing is transferring the blame to capacity of conflict misses - it does not reduce the miss probability (in fact, it may end up increase it)
Increasing the block size may also increase the cache latency and power consumption due to a more complex microarchitecture. Hence, this is not a preferred method to reduce miss probability - rather, an optimal cache block size is determined based on the workloads processed.
Cache Prefetching
This is the most common approach used to handle compulsory misses. The idea is simple: If there is way to predict the addresses that are going to be accessed by an instruction in advance, we can fetch them in advance into the cache. This idea is called cache prefetching. There are two types:
Hardware prefetching:
Here, we add some logic in hardware to analyze memory patterns and predict which cache lines will be needed next. A simple approach could be this: If there is a memory request to cache line with memory address 100, prefetch the next 4 cache lines (the assumption here is spatial locality).
At first glance, always prefetching seems like a great idea - but it comes at a cost: the power consumption increases. In the above example, let’s say we never use the 4 cache lines that were prefetched - performance would be unaffected, but the power consumed to predict which cache lines to prefetch, and actually fetch the cache lines is a waste. This is a key trade-off, especially for battery operated devices like smartphones.
Ideally, our hardware prefetcher should only fetch cache lines which are really needed - this reduced the miss probability (improve performance), at zero additional power cost. Hence, cache prefetching has been a hot research topic in computer architecture, and today’s caches use sophisticated protocols with high prediction accuracy.
Software prefetching
Hardware prefetching is a good general approach, but as I mentioned earlier, the additional power cost may be unacceptable in some cases. The main issue with hardware prefetchers is that they do not have visibility of the entire workload. There are two entities that have this visibility:
The programmer: You code could explicitly ask the processor to prefetch certain data into the cache before executing the commands
The compiler: A smart compiler could insert prefetch commands in the assembly code that the processor executes.
Such methods fall under software prefetching, and are widely deployed in today’s processors.
How to reduce capacity misses:
Make the cache bigger
This is the most obvious approach - but as you might expect, it comes at the cost of additional latency and power consumption. But having very small caches is not a good idea - based on the workload, the memory hotspot (part of code with most memory accesses) is analyzed, and the minimum capacity is decided based on the number of addresses needed to optimize performance for the hotspot. Cache sizes also depend on microarchitecture and technology limitations - for each semiconductor node, what is the maximum cache size to keep latency below a certain value. In summary, deciding the right cache size involves a lot of trade-offs, and is a key part of performance analysis in computer architecture teams.
How to reduce conflict misses:
Better cache address mapping
As I described earlier, conflict misses happen when a cache block was removed, despite there being space in the cache (If the cache was full, it would be a capacity miss). So by changing the way a memory address is mapped to a cache location, we should be able to avoid conflict misses. I covered the topic of cache mapping in detail in my previous post - mapping strategies vary from no flexibility in choosing index (Direct Mapped) to full flexibility (Fully Associative). A fully associative cache allows any memory address to map to any available cache block - hence, using a fully associative cache will ensure ZERO conflict misses. However, due to the hardware complexity, only very small caches can be made fully associative - and small caches are likely to increase the number of capacity misses - so there are tradeoffs to be made here as well.
Better cache replacement policies
As I mentioned earlier, using a fully associative mapping is not realistic for bigger caches. If we cannot ensure that all cache blocks are used effectively, the next best thing is to remove cache blocks which are not needed anymore to reduce the probability of a conflict. I introduced cache replacement policies in my previous post - these are the protocols followed to decide which cache block to remove when a new one needs to be added. By using a smarter replacement policy, we can evict unnecessary blocks and keep the number of conflicts to a minimum.
Smaller cache blocks
Since the cache has a fixed size, having a bigger block size (more addresses within one block) will result in fewer cache indices. When this happens, the impact of cache mapping worsens. For example, let’s say we have two caches that can hold 80 memory locations. The first cache has a block size of 4, which means it has 20 indices. The second cache, with block size 8, will have 10 indices. In this case, the second cache is more congested - the probability of conflicts is higher. Hence smaller block size is better.
Note that it directly contradicts point 1 for compulsory misses - although reducing cache block size can decease the number of conflict misses, it will increase the number of compulsory misses. So this approach should be used carefully.
Approach 2: Reducing the Miss Penalty
Despite all efforts to reduce the number of cache misses, they are bound to happen - even if we have the perfect prefetching logic, and a fully associative cache, and an ideal replacement policy, there are going to be certain workloads where all the required data cannot be kept in the cache (And in reality, perfect techniques don’t exist for either anyway). What this means is: We also need to worry about the number of additional clock cycles that we are spending when a cache miss takes place. Let’s look at some ways to reduce the miss penalty in this section.
Multi-level caches
This is a very fundamental idea of caching that has taken me very long to get to. Whenever I have mentioned memory system so far, I have assumed the following: The processor talks to the cache, and the cache interacts with the main memory. But real systems are more complicated - they have many levels of caches. This scheme is called multi-level caching, and has many benefits - the fundamental one being that it reduces the miss penalty.
The convention for naming caches is the letter ‘L’ followed by their position w.r.t the processor. So if we assume a system with 2 caches, this would include the processor, L1 cache (the one directly interacting with the processor), L2 cache (the extra cache level), and the main memory. This is shown in the below diagram (note, this is similar to the diagram in my previous post, but there are two cache levels now)
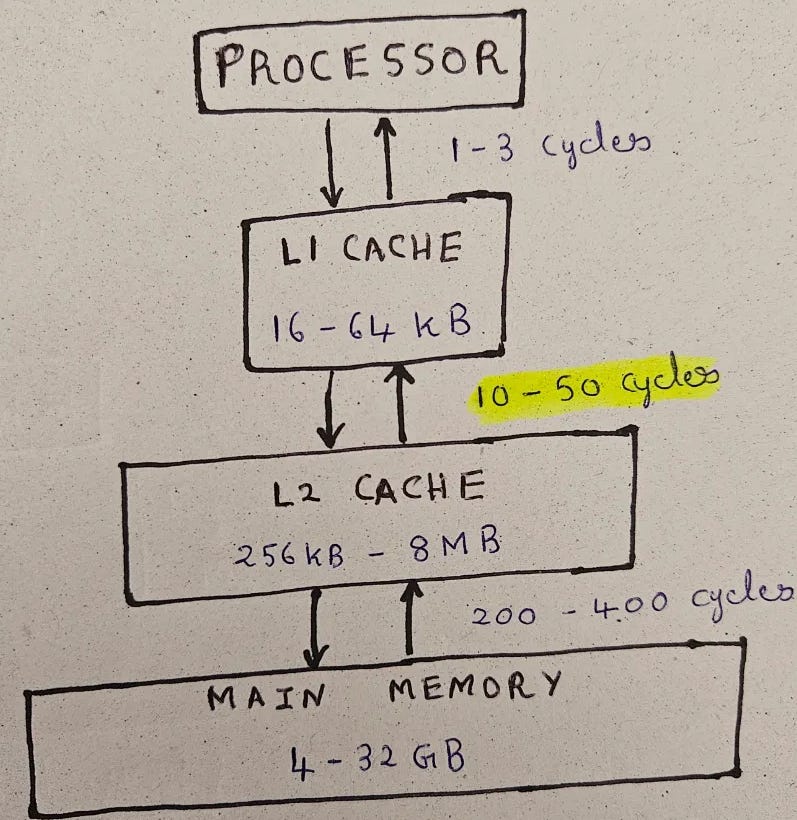
To understand how multi-level caching impacts miss penalty, let’s consider the AMAT equation from the start of this post:
AMAT = T_hit + (P_miss * T_miss)
Here, T_miss, (Miss Penalty) depends on the latency of the next stage. Since AMAT is computed w.r.t the processor, the latency comes from L1 cache. We can rewrite the equation as:
AMAT_processor = T_hit_L1 + (P_miss_L1 * T_miss_L1)
T_hit_L1 is the hit latency of L1 cache, which is usually low (1-3 cycles)
T_miss_L1 is the more interesting variable - without the L2 cache, it would be same as the main memory latency (200 - 400 cycles). However, due to the extra cache level, the miss penalty for L1 cache is same as the AMAT for the L1 cache from the L2 cache. This can be computed as:
AMAT_L1 = T_hit_L2 + (P_miss_L2 * T_miss_L2)
Here, T_miss_L2 is the component that comes from slow main memory access (L2 miss would mean accessing main memory). However, we now have some data in L2 cache which could result in a cache hit: Hit latency from L2 cache is much smaller. Hence, AMAT_L1 would be much better (typically 10-50 cycles).
In other words, we can represent the AMAT for the processor as:
AMAT_processor = T_hit_L1 + (P_miss_L1 * AMAT_L1)
-> AMAT_processor = T_hit_L1 + (P_miss_L1 * T_hit_L2 + (P_miss_L2 * T_miss_L2))
Roughly speaking, the probability that we need a slow memory access is now P_miss_L1 * P_miss_L2 - which would be much smaller that P_miss_L1 (in the single cache case). This way, we are able to reduce miss penalty using additional cache levels.
This is a quick introduction to multi-level caches. The topic of cache hierarchy has other complexities like Inclusivity that affect performance - I will cover them some other time.
Victim cache
Imagine that you have a set associative L1 cache where each set can hold 4 cache blocks. The processor is executing a workload where 5 cache blocks needs to be accessed repeatedly. In this case, request to access one of the cache blocks will always result in a miss (could be more based on the eviction policy). Even if we have an L2 cache that can provide this cache block, it still has more than 10 times the latency of the L1 cache. For such cases, adding a victim cache helps.
A victim cache is a small, fully associative cache (usually with a capacity under 100 cache blocks) that works as a partner to the L1 cache. The role of the victim cache is to hold cache blocks that were recently evicted by the L1 cache. In the above example, when the 5th cache block is accessed, one of the cache blocks from the set needs to be evicted. If a victim cache is present, the cache block can be moved there - so even though the next access to this block results in an L1 cache miss, it is a hit in the victim cache. Typically, when the processor sends a memory request, both L1 and victim caches are accessed in parallel. Due to the small size, a victim cache access is very fast - hence, L1 cache miss penalty is about the same as L1 cache hit latency if the cache block is present in the victim cache.

An obvious question here could be: If both L1 and victim caches are accessed in parallel, and have similar latencies, then why not just make the victim cache bigger. There are 3 key reasons why this won’t work:
A bigger L1 cache typically means more sets (assuming a set associative cache). This might help reduce capacity misses in caches, but conflict misses will still have a high miss penalty. Victim cache is used to reduce the miss penalty of conflict misses.
One could argue that by using a bigger L1 cache, the associativity can also be increased in a way that conflict misses are reduced. This is possible, but as I covered in my earlier post, increasing associativity adds complexity to the cache control logic. A victim cache is better because it allows you to keep the same associativity, but handles certain corner cases where you need the extra associativity.
Finally, increasing cache size makes the cache slower - so a parallel access to 2 different cache is better is performance is your main goal.
As I mentioned earlier, the victim cache is very small, so a good protocol is needed to decide which of the evicted cache blocks should be placed there. One approach is to use counters in the L1 cache to tracks which sets are used more often, and only move evicted blocks from those sets to the victim cache. This is another hot research topic in computer architecture.
Some other approaches to improve cache performance:
This is an ever evolving field, and every new workload introduces new methods to reduce memory access time. I’ll briefly mention a few such methods:
Early restart:
Normally, when a processor requests access to an address, and it is a miss, the cache waits for all addresses in the cache block to be populated. The cache to main memory bandwidth is usually smaller than the block size - so the cache needs multiple read transactions from the main memory to get populated. This can be optimized slightly if the cache responds to the processor as soon as the required address is ready, even if it takes more cycles for the cache block to be fully updated.
Subblock placement
The idea is similar to early restart - but here, instead of just responding faster to the processor, the cache entirely eliminates request for the unused words in the cache block (which also reduced power consumption). However, such incomplete blocks would need special handling, especially during hit/miss checks - which could increase the hit latency of the cache.
Nonblocking caches
In a simple cache, during a cache miss, all other requests to cache are blocked till the miss request is served. However, with sufficiently advanced caches (called Nonblocking caches), we can allow other requests to continue in parallel as the cache is handling the miss. This will reduce the average memory access time across multiple cache requests (but needs complicated protocols to handle multiple requests)
Conflict detection mechanisms
There are some advanced techniques to handle conflicts, like Bypass in Case of Conflict (BCC) and Set Conflict Cache (SCC)
Compiler optimizations
Techniques like Loop unrolling, Loop interchange and Loop fusion can help the compiler generate more friendly memory access patterns
Programmer hacks
Design programs with optimal data structures and memory access patterns
Instruction versus Data cache
I’ll end this post talking about how instructions and data memory are managed in processors. The fundamental idea of caching remain the same for both data and instructions (When I used data earlier, I refer to both instructions and data together). However, data and instructions have different access patterns.
Instructions:
Typically accessed sequentially
Read-only (in most cases)
More predictable access patterns
Data:
Often accessed non-sequentially
Subject to both reads and writes
Less predictable access patterns
Hence, it makes a lot of sense to separate the caches for Instruction and Data - particularly at the L1 level. The Instruction cache (I-cache) has the following special properties:
Optimized for reads
Cache block may include annotations specific to instruction decoding (typically added by compiler so that hardware can run more efficiently)
Aggressive prefetching, since access is mostly sequential
Such optimizations make the I-cache very effective. Usually, L2 and other memory levels are shared by instructions and data.
A special type of I-cache is called Trace cache. In trace caches, instead of storing the plain instructions, a decoded representation of the instruction is stored. This can allow optimal use of the cache (storing only the required instruction fields), and can also better support branch instruction handling.
The current post ends here, but there’s a lot more to know about caches. So subscribe, and stay tuned for more.
References:
Next-Gen Computer Architecture: Till the End of Silicon, by Prof. Smruti R Sarangi - https://www.cse.iitd.ac.in/~srsarangi/advbook/index.html
https://www.knownhost.com/blog/what-is-a-cache-miss-and-how-can-you-reduce-them/
https://www.cs.cmu.edu/afs/cs.cmu.edu/user/tcm/www/thesis/subsubsection2_10_2_2_1.html
https://people.eecs.berkeley.edu/~randy/Courses/CS252.S96/Lecture17.pdf
Wonderful! Thank you for writing! Was eagerly waiting for part two on Caches!